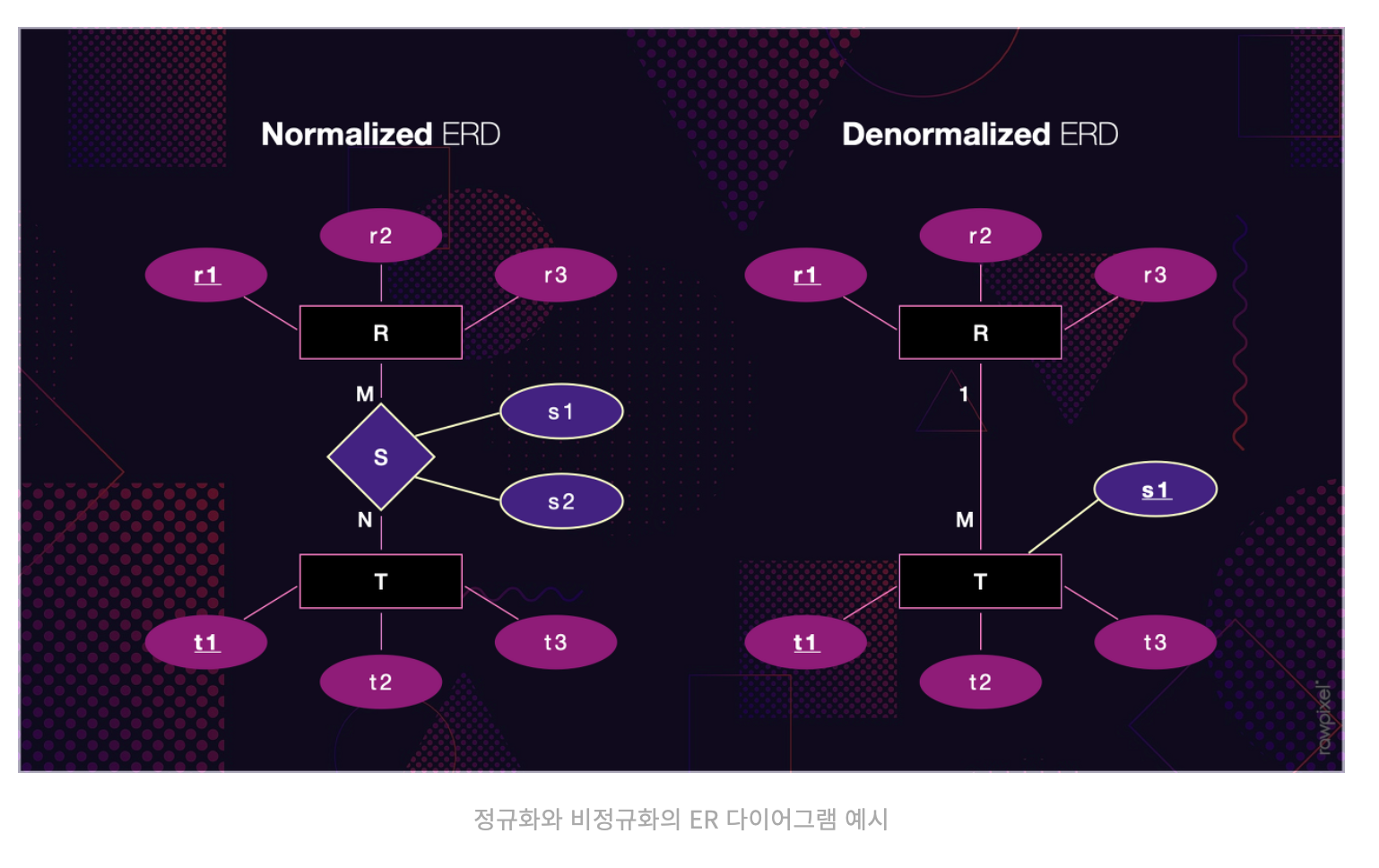
정규화와 비정규화
in Legacy on ECMAScript
원문 에 제 생각을 좀더 첨가 해보았습니다. 정말 좋은 글 같습니다.
정규화 데이터베이스(normalized database)는 중복을 최소화 하도록 설계된 데이터베이스이다. 반면 비정규화 데이터베이스(denormalized database)는 읽는 시간을 최적화 하도록 설계된 데이터베이스이다.
정규화 데이터베이스
- 같은 데이터는 데이터베이스 내에 하나 정도만 놓으려고 노력한다.
- 하지만 상당수의 일상적 질의를 처리하기 위해 JOIN을 많이 하게 되는 단점이 있다.
비정규화 데이터베이스
- 관계형 데이터베이스(relational database)를 사용하는 경우, JOIN 연산의 비용을 줄일 수 있다.
- 비정규화는 높은 규모 확장성을 실현하기 위해 자주 사용되는 기법이다
- 중복이 너무 많아지면 데이터베이스 자원 낭비도 심해진다.
비정규화란? (Denormalization)
하나 이상의 테이블에 데이터를 중복해 배치하는 최적화 기법이다.
시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해 정규화된 데이터 모델을 통합, 중복, 분리하는 과정으로, 의도적으로 정규화 원칙을 위배하는 행위이다.
예를 들어, Courses와 Teachers라는 테이블로 이루어진 정규화된 데이터베이스를 생각해 보자. Courses 테이블에는 teacherlD를 둘 수는 있어도, teacherName이라는 필드를 두지는 않을 것이다. 왜냐하면 teacherID를 가지고 조인을 하여 teacher의 데이터를 가져오기 때문이다. 따라서 강좌 정보와 교사 이름을 함께 나열하고 싶은 경우에는 꼭 이 경우가 아니더라도 강좌 정보와 교사 정보를 모두 나열하고 싶은 경우에는 두 테이블을 조인해야 한다. 어떤 면에서는 멋진 방법이다. 교사가 자신의 이름을 바꿀 경우, 한 곳의 데이터만 갱신하면 된다. 하지만 이 방법의 단점은 테이블이 아주 클 경우 조인을 하느라 불필요할 정도로 많은 시간을 낭비하게 된다는 것이다.
비정규화는 다른 타협안을 내놓음으로써 그런 단점을 해소하고자 한다. 어느 정도의 데이터 중복이나 그로 인해 발생하는 데이터 갱신 비용은 감수하는 대신 조인 횟수를 줄여 한층 효율적인 쿼리를 날릴 수 있도록 하겠다는 것이다.
장점
- 조인 비용이 줄어들기 때문에 빠른 데이터 조회
- 데이터를 한곳에 몰아 놓으면 살펴봐야할 테이블이 적어진다.
- 원래 Course와 Teachers라는 테이블에 따로따로 있어야할 데이터들이 그냥 Course와 Teachers테이블 둘다에 존재해버리거나 한곳에 이미 존재를 해버리면 굳이 볼 필요없는 테이블은 보지 않아도된다.
단점
- 삽입 비용이 높음
- 정규화된 테이블에서는 한번만 삽입을 하면 되지만 비정규화는 두 번 이상의 삽입쿼리를 날릴 확률이 높다.
- 데이터 갱신 또는 삽입 코드를 작성하기 어려워짐
- 위와 같은 이유인데 그냥 일이 두배로 늘어버리니까 확실히 정규화 데이터베이스보다 난이도도 높아지게 된다. 신경써야할게 많아지기 때문이다.
- 데이터 간의 일관성이 깨어질 수 있다. 어느 쪽이 올바른 값인가?
- 나중에 어떤 데이터를 실제 쿼리의 결과로 사용해야하는것인가 헷갈릴수 있다. 삽입을 한쪽만 하는 쿼리를 뒤늦게 발견했거나, 삭제를 한쪽만 하는 쿼리를 뒤늦게 발견해서 이미, 데이터 자체가 신빙성이 없어지고나서야 이러한 오류를 알아챌수 있는것이다. 나는 이게 제일 큰 문제라고 생각한다. 빠르면 빠를수록 UX는 좋아질수 있을것같다. 하지만 결국 빠르게 쿼리를 해서 받은 결과가 정확하지 못한 정보라면? 그게 만약 회사 수익과 직결이 되어있다면 더 큰문제가 발생하기때문에 내 생각이 정규화를 선호하게 되는거 같다. 근데 물론 상황에 따라 달라질것 같다.
- 데이터를 중복하여 저장하므로 더 많은 저장 공간이 필요
비정규화 대상
- 자주 사용되는 테이블에 액세스하는 프로세스의 수가 가장 많고, 항상 일정한 범위만을 조회하는 경우
- 테이블에 대량 데이터가 있고 대량의 범위를 자주 처리하는 경우, 성능 상 이슈가 있을 경우
- 테이블에 지나치게 조인을 많이 사용하게 되어 데이터를 조회하는 것이 기술적으로 어려울 경우
- 대부분의 대규모 IT 업체의 경우처럼, 규모 확장성(scalability)을 요구하는 시스템의 경우 거의 항상 정규화된 데이터베이스와 비정규화된 데이터베이스를 섞어 사용한다. SQL과 NoSQL을 동시에도 사용한다고 하니 상황에 따라 맞는 전략, DB를 사용하는것이 좋은것 같다.
주의점
- 반정규화를 과도하게 적용하다 보면 데이터의 무결성이 깨질 수 있다.
- 데이터의 무결성은 데이터의 정확성을 말한다. 결함이 없다라는 뜻
- 입력, 수정, 삭제의 질의문에 대한 응답 시간이 늦어질 수 있다.
이상 현상 (Anomaly)
중복된 정보로 인해 발생하는 문제들을 이상 현상(Anomaly)이라 말한다.
- 삽입 이상(Insertion Anomaly) : 원하지 않는 자료가 삽입된다든지, 삽입하는데 자료가 부족해 삽입이 되지 않아 발생하는 문제점을 말한다.
- 삭제 이상(Deletion Anomaly) : 하나의 자료만 삭제하고 싶지만, 그 자료가 포함된 튜플 전체가 삭제됨으로 원하지 않는 정보 손실이 발생하는 문제점을 말한다.
- 갱신 이상(Modification Anomaly) : 정확하지 않거나 일부의 튜플만 갱신되어 정보가 모호해지거나 일관성이 없어져 정확한 정보 파악이 되지 않는 문제점을 말한다.
→ 이상 현상은 정규화를 통해 방지할 수 있다.
정규화 (normalized)
관계형 데이터베이스에서 중복을 최소화하기 위해 데이터를 구조화하는 작업이다. 좀 더 구체적으로는 하나의 종속성이 하나의 릴레이션에 표현될 수 있도록 분해해가는 과정이라 할 수 있다.
강사 column + 강의 column이 함께 있는 테이블을 강사 table + 강의 table로 분해해가는 과정이라고 할 수 있다.
한 릴레이션에 여러 Entity의 Attribute들을 혼합하게 되면 정보가 중복 저장되며, 저장 공간을 낭비하게 된다. 또한 중복된 정보로 인해 ‘갱신 이상’이 발생하게 된다.
update 할때 중복되는 데이터중 어느것을 update해야할지, delete할때는 어느것을 delete할지 모른다.
동일한 정보를 한 릴레이션에는 변경하고, 나머지 릴레이션에서는 변경하지 않은 경우 어느 것이 정확한지 알 수 없게 되는 것이다.
이러한 문제를 해결하기 위해 정규화 과정을 거친다. 정규화 과정을 거치게 되면 정규형을 만족하게 된다.
정규형
특정 조건을 만족하는 릴레이션의 스키마의 형태
제1 정규형, 제2 정규형, 제3 정규형, BCNF형, 제4 정규형, 제5 정규형이 존재한다.
차수가 높아질수록 만족시켜야 할 제약 조건이 늘어난다.
장점
- 데이터베이스 변경 시 이상 현상(Anomaly) 제거
- 저장 공간의 최소화 가능
- 효과적인 검색 알고리즘 생성 가능
- 데이터 삽입 시 릴레이션 재구성의 필요성 감소
- 데이터 구조의 안정성 및 무결성 유지
단점
- 릴레이션 간의 JOIN 연산 증가 → 이로 인한 질의에 대한 응답 시간 저하 JOIN으로 인한 연산이 얼마나 증가하는지는 추후 더 공부해서 다루도록 하겠습니다.
정규화의 원칙
- 정보의 무손실 표현
→ 하나의 스키마를 다른 스키마로 변환할 때 정보의 손실이 있어서는 안 된다.
분리의 원칙
→ 하나의 독립된 관계성은 하나의 독립된 릴레이션으로 분리시켜 표현해야 한다.
데이터의 중복성이 감소되어야 한다.
함수적 종속(Functional Dependency)
데이터들이 어떤 기준값에 의해 종속되는 것을 의미한다.
예를 들어 <수강> 릴레이션이 (학번 이름, 과목명)으로 되어 있을 때, '학번'이 결정되면 '과목명’에 상관없이 '학번'에는 항상 같은 '이름'이 대응된다. '학번에 따라 '이름'이 결정될 때 '이름'을 '학번'에 함수 종속적이라고 하며 '학번 → 이름'과 같이 된다
완전 함수적 종속 (추후 더 정확한 예로 다루기)
완전 함수적 종속은 어떤 속성이 기본키에 대해 완전히 종속적일 때를 말한다.
어떤 테이블 에서 속성 A가 다른 속성 집합 B 전체에 대해 함수적 종속이지만 속성 집합 B의 어떠한 진부분 집합 C(즉, C ⊂ B)에는 함수적 종속이 아닐 때 속성 A는 속성 집합 B에 완전 함수적 종속이라고 한다.
예를 들어 <수강> 릴레이션이 (학번, 과목명, 성적, 학년)으로 되어 있고 (학번, 과목명)이 기본키일 때, '성적'은 '학번'과 '과목명’이 같을 경우에는 항상 같은 '성적'이 온다. → 즉, '성적'은 '학번'과 '과목명’에 의해서만 결정되므로 '성적'은 기본키(학번, 과목명)에 완전 함수적 종속이 되는 것이다.
부분 함수적 종속 (추후 더 정확한 예로 다루기)
어떤 테이블 R에서 속성 A가 다른 속성 집합 B 전체에 대해 함수적 종속이면서 속성 집합 B의 어떠한 진부분 집합에도 함수적 종속일 때 속성 A는 속성 집합 B에 부분 함수적 종속이라고 한다.
반면에 ‘학년’은 ‘과목명’에 관계없이 ‘학번’이 같으면 항상 같은 ‘학년’이 온다. → 즉, 기본키의 일부인 ‘학번’에 의해서 ‘학년’이 결정되므로 ‘학년’은 부분 함수적 종속이라고 한다.
